GVFExplorer: Adaptive Exploration for Data-Efficient General Value Function Evaluations
NeurIPS, 2024
I’m a Research Scientist at
Lila Sciences
working at the intersection of reinforcement learning, LLMs, and life sciences. I work on adaptive curriculum-learning methods for multi-task training to improve data efficiency and enable capable generalist scientific models.
I earned my PhD at McGill University and
Mila
where I was advised by
Doina Precup
.Broadly, I am interested in building data-efficient, self-exploratory RL algorithms that scale robustly to complex environments.

Data-efficient, safe and reliable RL algorithms for complex environments.
Scalable RL for LLMs in life-science with focus on generalist reasoning.
Novel strategies for effective exploration including self-supervised settings.
Recent highlights.
I will be attending AI for Life Science Workshop, Barbados 2026.
Gave talk on "Adaptive Exploration for Data-Efficiency" at MSR, India.
Started internship at Microsoft Research (MSR) Amsterdam with Elise Van Der Pol in a molecular drug discovery.
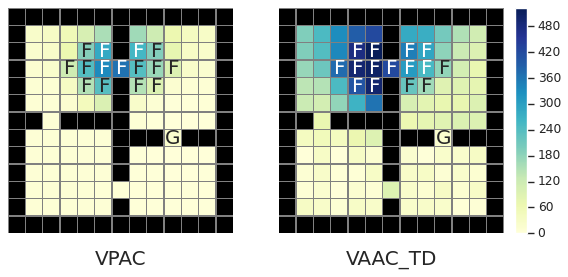
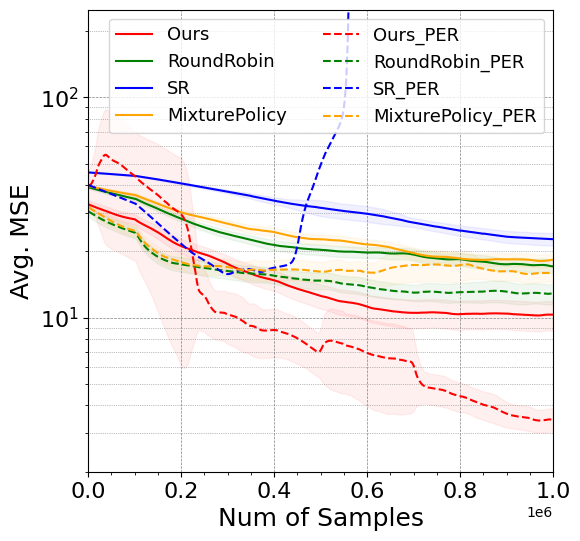
Paper “Adaptive Exploration for Data-Efficient General Value Function Evaluations” accepted at NeurIPS 2024.
Attending the TTIC workshop on “Adaptive Learning in Complex Environments”.
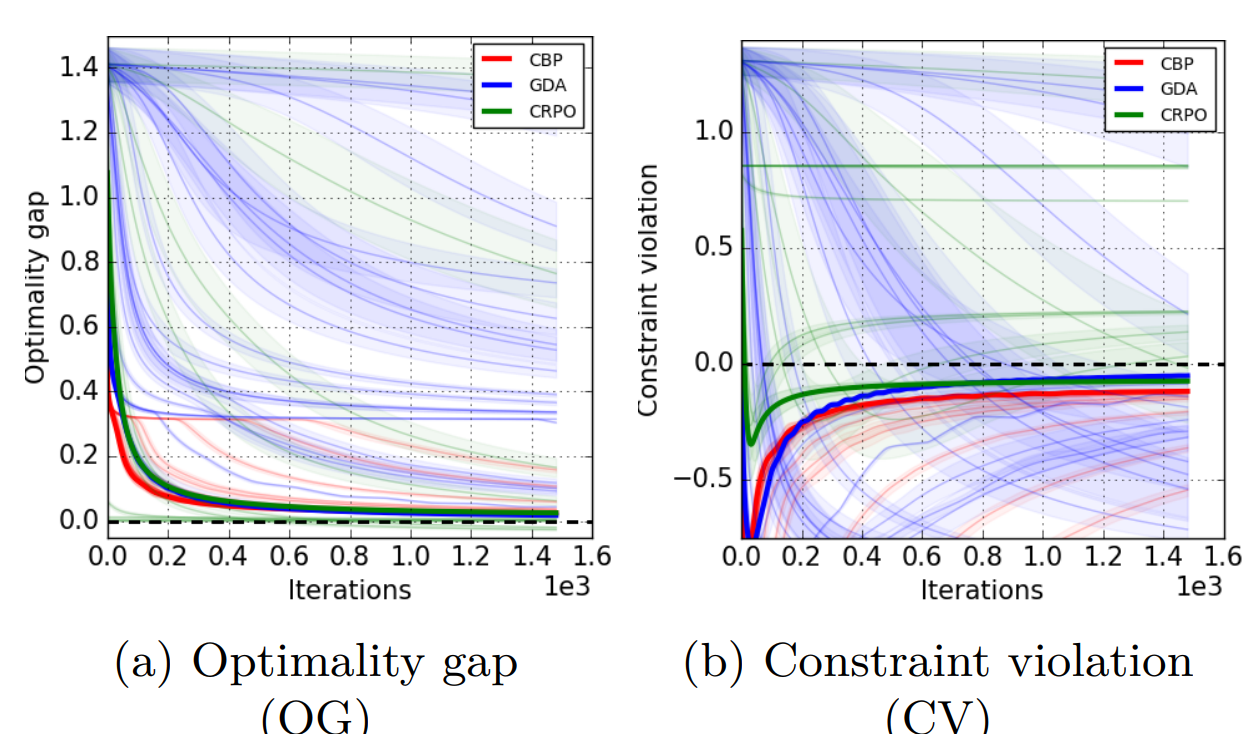
Gave a talk on “Towards Painless Policy Optimization for Constrained MDPs” at the Mila-RL Workshop.
Selected publications.